

กำลังมองหาบทความที่ให้ความรู้กันอยู่ใช่ไหม ว่า Duplicate Content คืออะไร ส่งผลเสียต่อการทำ SEO หรือไม่ มาดูกัน
เนื้อหาซ้ำ หนึ่งในความหนักใจที่มีมาอย่างยาวนานของเจ้าของเว็บทั้งหลาย ซึ่งหลังจากอ่านข้อมูลเกี่ยวกับเรื่องนี้มามากมาย หลายคนคงเริ่มกังวลว่าเว็บไซต์ของตัวเองตอนนี้เป็นเหมือนระเบิดเวลาที่พร้อมเกิดปัญหาอยู่ตลอดจากเนื้อหาซ้ำหรือเปล่า หรือเริ่มมีความกังวลเกี่ยวกับบทลงโทษของ Google กันแล้ว
แต่สบายใจได้ เพราะการทำเนื้อหาซ้ำไม่มีบทลงโทษที่ชัดเจน แต่ถึงอย่างนั้นจงจำไว้ว่าอาจทำให้เกิดปัญหา SEO ตามมาได้ ดังนั้นเว็บไซต์ที่รู้ตัวว่าเนื้อหาประมาณ 25 – 30 % บนหน้าเว็บของตัวเองเป็นบทความที่ซ้ำกัน ก็ควรรู้วิธีที่จะหลีกเลี่ยง และแก้ไขปัญหาดังกล่าวนั่นเอง
ในบทความนี้ จะมาพูดถึงหัวข้อเกี่ยวกับ Duplicate Content ดังต่อไปนี้
- เนื้อหาซ้ำ (Duplicate Content) คืออะไร
- เพราะเหตุใด Duplicate Content ถึงไม่ส่งผลดีต่อ SEO
- Google มีบทลงโทษสำหรับเนื้อหาที่ซ้ำกันหรือไม่
- สาเหตุทั่วไปที่ทำให้เกิดปัญหา Duplicate Content
- วิธีตรวจสอบ และแก้ไขเนื้อหาที่ซ้ำกันบนเว็บของตัวเอง
- วิธีตรวจสอบ และแก้ไขเนื้อหาที่ซ้ำกันบนเว็บไซต์อื่น
เนื้อหาซ้ำ (Duplicate Content) คืออะไร
คือ เนื้อหาที่เหมือนกันแทบทุกประการ หรือเกือบจะซ้ำกันที่ปรากฏอยู่บนเว็บไซต์มากกว่าหนึ่งแห่ง ซึ่งอาจเกิดขึ้นได้บนเว็บไซต์โดเมนเดียวกัน หรือโดเมนอื่นก็ได้
ยกตัวอย่างเช่น หากเรามีการโพสต์บทความนี้อีกครั้งบนหน้าเว็บอื่นของตัวเอง หรือบนเว็บไซต์อื่น นั่นก็เรียกได้ว่าเป็นเนื้อหาที่ซ้ำกันแล้ว แต่ Google ก็ระบุไว้ชัดเจนว่าเนื้อหาที่ซ้ำกันส่วนใหญ่ไม่ได้เกิดจากการหลอกลวงซะทีเดียว
เพราะเหตุใด Duplicate Content ถึงไม่ส่งผลดีต่อ SEO
Duplicate Content อาจส่งผลเสียต่อประสิทธิภาพของ SEO ด้วยเหตุผลบางประการดังนี้
- เกิด URL ไม่พึงประสงค์ หรือไม่เป็นมิตรในผลการค้นหา
- ลดบทบาท Backlinks
- สิ้นเปลืองงบประมาณรวบรวมข้อมูล
- เนื้อหาที่คัดลอกไปอาจมีอันดับเหนือกว่าเว็บไซต์ต้นฉบับ
โดยลำดับต่อไปเราจะมาลงรายละเอียดแต่ละหัวข้อให้ลึกยิ่งขึ้นกัน
เกิด URL ไม่พึงประสงค์ หรือไม่เป็นมิตรในผลการค้นหา
ลองจินตนาการดูว่ามีหน้าเว็บเดียวกันที่มี URL แตกต่างกันถึง 3 แห่ง ตัวอย่างเช่น
- domain.com/page/
- domain.com/page/?utm_content=buffer&utm_medium=social
- domain.com/category/page/
ซึ่งความเป็นจริงลิงก์รายการแรกควรจะปรากฏในผลการค้นหา แต่ Google อาจเกิดความสับสน และหากเป็นเช่นนั้นก็กลับกลายเป็นว่า URL ไม่พึงประสงค์อื่น ๆ จะขึ้นมาแทนนั่นเอง
โดยผู้คนมักตัดสินใจไม่กดคลิกลิงก์ที่ดูไม่เป็นมิตร ดังนั้นจึงเป็นเหตุผลที่ทำให้เราได้รับจำนวนการคลิกน้อยลงนั่นเอง
ลดบทบาท Backlinks
หากคอนเทนต์เดียวกันไปปรากฏอยู่บนหลาย URL โดยแต่ละ URL เหล่านั้นอาจดึงดูด Backlinks ของตัวเอง ส่งผลให้เกิดการแบ่งสัดส่วนของ Backlinks กันนั่นเอง
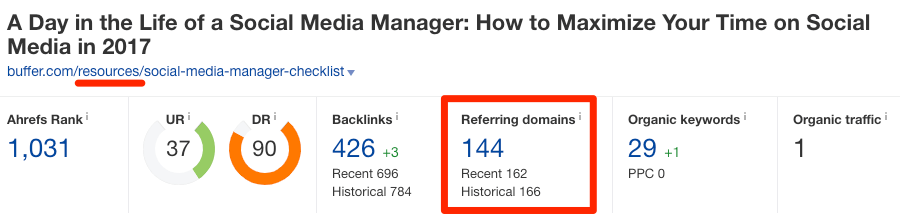
หากต้องการเห็นภาพมากขึ้น สามารถดูตัวอย่างได้จากลิงก์ของเว็บไซต์ buffer.com ได้ดังนี้
https://buffer.com/library/social-media-manager-checklist
https://buffer.com/resources/social-media-manager-checklist
โดยเนื้อหาในทั้งสองลิงก์นี้แทบจะเหมือนกันทุกประการ และมีโดเมนอ้างอิง หรือลิงก์จากเว็บไซต์ที่ไม่ซ้ำกันทั้งหมด 106 และ 144 โดเมน ตามลำดับ

หากเกิดเหตุการณ์แบบนี้ก็ยังไม่ต้องตกใจไป เพราะ Google เองก็มีวิธีจัดการกับ Duplicate Content เช่นเดียวกัน
อธิบายง่าย ๆ คือ เมื่อตรวจพบเว็บไซต์ที่เนื้อหาซ้ำกัน Googe จะจัด URL ของเว็บเหล่านั้นให้อยู่ในกลุ่มเดียวกัน จากนั้นก็จะเลือก URL ที่คิดว่า ‘ดีที่สุด’ ออกมา เพื่อเป็นตัวแทนกลุ่มในผลการค้นหา เช่น อาจเลือกลิงก์ที่ได้รับความนิยมมากที่สุดนั่นเอง โดยเราจะเรียกขั้นตอนเหล่านี้ว่า canonicalization
ดังนั้นจากเคสตัวอย่างด้านบน Google ก็ควรจะแสดงผล URL รายการเดียวในผลการค้นหาทั่วไป และระบุแหล่งที่มาของโดเมนอ้างอิงทั้งหมดในกลุ่มให้กับ URL นั้น
แต่หากดูจากภาพด้านล่างผลปรากฏว่า ทั้ง 2 URL ถูกนำมาจัดอันดับทั้งหมดในคีย์เวิร์ดที่คล้ายกัน
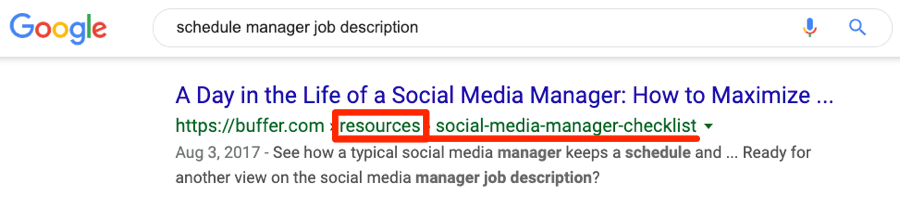

ดังนั้นบทสรุปคือ ดูเหมือนว่า Google เองก็มีแนวโน้มที่จะไม่ทำการรวมส่วนต่าง ๆ ของลิงก์ไว้ที่ URL เดียวกันนั่นเอง
คำอธิบายเพิ่มเติม
เราไม่สามารถแน่ใจได้เลยว่า Google มองเห็นทั้งสอง URL ด้านบนเป็นอย่างไร เนื่องจากเราไม่มีสิทธิ์เข้าถึงบัญชีของเว็บไซต์ Buffer ได้ ซึ่งอาจเป็นไปได้ว่า Google รับรู้แล้วว่า URL ทั้งสองนี้ซ้ำกัน และหนึ่งในนั้นกำลังจะหายไปจากผลการค้นหาในไม่ช้านั่นเอง
สิ้นเปลืองงบประมาณรวบรวมข้อมูล
Google จะทำการค้นหาคอนเทนต์บนเว็บไซต์ของเราผ่านการรวบรวมข้อมูล ซึ่งหมายความว่า จะมีการตรวจสอบตั้งแต่หน้าเว็บเก่าไปถึงอันใหม่ นอกจากนี้ยังมีการรีเช็กเว็บไซต์ที่เคยรวบรวมไปแล้วครั้งหนึ่งเพื่อดูว่ามีการเปลี่ยนแปลงอะไรหรือไม่อีกด้วย
ดังนั้นการมีหน้าเว็บที่เนื้อหาซ้ำกันเป็นเพียงการเพิ่มงานที่ไร้ประโยชน์ให้กับ Google เท่านั้น ซึ่งอาจส่งผลต่อความเร็ว และความถี่ในการรวบรวมข้อมูลของเว็บไซต์ใหม่ หรือหน้าเว็บที่มีการอัปเดต และทำให้เกิดความล่าช้าในการจัดทำตัวชี้วัดของแต่ละหน้านั่นเอง
เนื้อหาที่คัดลอกไปอาจมีอันดับเหนือกว่าเว็บไซต์ต้นฉบับ
ในบางโอกาสเราอาจอนุญาตให้เว็บไซต์อื่นเผยแพร่เนื้อหาซ้ำของเราได้ ซึ่งเป็นเรื่องไม่ผิดอะไร แต่บางครั้งก็อาจมีเว็บไซต์ที่แอบคัดลอกเนื้อหา และนำไปเผยแพร่โดยไม่ได้รับอนุญาต
ซึ่งทั้งสองเหตุการณ์นี้ล้วนเป็นปัจจัยที่นำไปสู่การเกิด Duplicate Content ที่ซ้ำกันในหลายโดเมน โดยปกติแล้วมักไม่ทำให้เกิดปัญหาตามมาอย่างแน่ชัด แต่อาจเริ่มเห็นผลก็ต่อเมื่อเว็บไซต์ที่มีการคัดลอกคอนเทนต์ไปลงกลับมีอันดับดีกว่าหน้าต้นฉบับที่คัดลอกไปนั่นเอง และถึงแม้ว่าจะเป็นเหตุการณ์ที่เกิดขึ้นไม่บ่อยนัก แต่ก็มีโอกาสเกิดขึ้นได้
Google มีบทลงโทษสำหรับเนื้อหาที่ซ้ำกันหรือไม่
Google ได้ประกาศอย่างเป็นทางการหลายครั้งแล้วว่า ไม่มีบทลงโทษสำหรับการเขียนเนื้อหาซ้ำกัน แต่นั่นก็ไม่ถูกต้องทั้งหมด หากเนื้อหาที่ซ้ำกันเกิดจากความไม่ตั้งใจ หรือการสแปมโดยไม่เจตนา ก็จะไม่ถูกลงโทษ แต่หากเกิดจากความตั้งใจ ก็อาจมีบทลงโทษได้
Google ยืนยันแล้วว่า :
Google สามารถรับรู้ได้ว่ามีการแสดงเนื้อหาที่ซ้ำกันโดยเจตนา เพื่อบิดเบือนการจัดอันดับ และหลอกลวงผู้ใช้งาน โดยมีมาตรการปรับเปลี่ยนความเหมาะสมในการจัดทำดัชนี และการจัดอันดับเว็บไซต์ที่เกี่ยวข้อง ซึ่งอาจส่งผลกระทบต่อการจัดอันดับ หรือทำให้เว็บไซต์นั้นถูกลบออกจากตัวชี้วัดของ Google ทั้งหมด ทำให้กรณีนี้เว็บไซต์จะไม่ปรากฏในผลการค้นหาอีกต่อไป
ซึ่งคำถามต่อไปคือ มีอะไรบ้างที่ถือเป็น “เจตนาที่แสดงให้เห็นว่าต้องการบิดเบือนการจัดอันดับ และหลอกลวงผู้ใช้งาน”
โดย Google มีข้อมูลมากมายเกี่ยวกับเรื่องนี้ ซึ่งสามารถหาอ่านเพิ่มได้ที่นี่ แต่โดยพื้นฐานแล้วสามารถสรุปเป็นข้อ ๆ ได้ดังนี้
- จงใจสร้างเพจ โดเมนย่อย หรือโดเมนหลายรายการที่มีเนื้อหาซ้ำกันจำนวนมาก
- มีการเผยแพร่เนื้อหาที่คัดลอกมาจำนวนมาก
- มีการเผยแพร่เนื้อหา Affiliate ที่คัดลอกมาจาก Amazon หรือแหล่งอื่น โดยไม่มีการจ่ายค่าตอบแทน
และตามที่ได้กล่าวไปข้างต้น อย่างไรก็ตามเนื้อหาที่ซ้ำกันก็ยังส่งผลเสียต่อประสิทธิภาพของ SEO อยู่ดี ถึงแม้จะไม่มีบทลงโทษที่แน่ชัดก็ตาม
สาเหตุทั่วไปที่ทำให้เกิดปัญหา Duplicate Content
สาเหตุที่ทำให้เกิด Duplicate Content ไม่ได้มาจากปัจจัยเดียว แต่เกิดจากสิ่งเหล่านี้
การใส่ฟิลเตอร์ หรือระบบนำทางแบบประกอบ (filtered navigation)
Filtered navigation คือองค์ประกอบที่ช่วยให้ผู้ใช้งานสามารถคัดกรอง และจัดหมวดหมู่ในเว็บได้ โดยนิยมใช้กันมากบนเว็บไซต์อีคอมเมิร์ซ
ซึ่งระบบนำทางนี้จะเพิ่มพารามิเตอร์ต่อท้าย URL เสมอ

เนื่องจากปกติแล้วฟิลเตอร์เหล่านี้มักมีหลายชุด การนำทางแบบประกอบจึงมักส่งผลให้เกิดเนื้อหาซ้ำ หรือใกล้เคียงกันจำนวนมาก
สามารถดูตัวอย่างได้จากสองลิงก์นี้
bbclothing.co.uk/en-gb/clothing/shirts.html?new_style=Checked
bbclothing.co.uk/en-gb/clothing/shirts.html?Size=S&new_style=Checked
ที่ URL ไม่เหมือนกัน แต่คอนเทนต์ที่อยู่ด้านในนั้นแทบจะเหมือนกันทั้งหมด
นอกจากนี้ลำดับของพารามิเตอร์ยังไม่สำคัญด้วย เนื่องจากสามารถเข้าถึงเว็บไซต์เดียวกันได้จากสองลิงก์ดังนี้
bbclothing.co.uk/en-gb/clothing/shirts.html?new_style=Checked&Size=XL
bbclothing.co.uk/en-gb/clothing/shirts.html?Size=XL&new_style=Checked
วิธีแก้ปัญหา
ระบบนำทางแบบประกอบ เป็นเหมือนเขาวงกตที่ซับซ้อน หากเริ่มเกิดความสงสัยว่าปัญหา Duplicate Content อาจเกิดจากสาเหตุนี้ สามารถหาอ่านข้อมูลเพิ่มเติมได้ที่นี่
การติดตามพารามิเตอร์
URL ที่กำหนดพารามิเตอร์ถูกใช้เพื่อวัตถุประสงค์ในการติดตามด้วย โดยอาจใช้พารามิเตอร์ UTM เพื่อติดตามการเข้าชมจากแคมเปญจดหมายข่าวใน Google Analytics
ตัวอย่างเช่น : example.com/page?utm_source=newsletter
วิธีแก้ปัญหา
ให้ทำการ Canonicalize URLs เป็นเวอร์ชันที่เป็นมิตรต่อ SEO โดยไม่ต้องพึ่งการติดตามพารามิเตอร์
Session IDs
ตัว Session IDs จะช่วยจัดเก็บข้อมูลที่เกี่ยวข้องกับผู้เยี่ยมชมของเรา โดยมักเขียนเป็นข้อมูลตัวอักษรยาว ๆ ต่อท้าย URL ดังนี้
ตัวอย่าง: example.com?sessionId=jow8082345hnfn9234
วิธีแก้ปัญหา
เหมือนกับด้านบนเลยคือ ให้ทำการ Canonicalize URLs เป็นเวอร์ชันที่เป็นมิตรต่อ SEO
HTTPS กับ HTTP และ Non www กับ www
เว็บไซต์ส่วนใหญ่สามารถใช้งานได้จากหนึ่งในสี่รูปแบบดังนี้
https://www. example.com (HTTPS, www)
https:// example.com (HTTPS ไม่ใช่ www)
http://www. example.com (HTTP, www)
http:// example.com (HTTP ไม่ใช่ www)
ซึ่งหากเลือก HTTPS ก็จะเป็นเหมือนสองรายการแรกที่สามารถเลือกใช้ www หรือ ไม่มี www ก็ได้
ดังนั้นหากมีการตั้งค่าเซิร์ฟเวอร์ที่ไม่ถูกต้อง โดยสามารถเข้าถึงหน้าเว็บเดียวกันได้จากลิงก์สองรูปแบบขึ้นไป ก็มีโอกาสที่จะนำไปสู่ปัญหาเนื้อหาซ้ำนั่นเอง
วิธีแก้ปัญหา
ใช้การเปลี่ยนเส้นทาง เพื่อให้แน่ใจว่าเว็บไซต์ของเราสามารถเข้าถึงได้จากที่เดียวเท่านั้น
การใช้ตัวพิมพ์ใหญ่ – เล็กบน URL
Google มีการคำนึงถึงตัวพิมพ์ใหญ่ และเล็กบน URL นั่นหมายความว่า URL ทั้ง 3 อันด้านล่างนี้แตกต่างกันทั้งหมด
example.com/page
example.com/PAGE
example.com/pAgE
วิธีแก้ปัญหา
ให้ยึดมั่นกับการลิงก์ภายในเว็บไซต์เท่านั้น และอย่าทำการลิงก์ไปยัง URL หลายเวอร์ชัน หากเบื้องต้นทำแล้วยังไม่สามารถแก้ไขได้ อาจลองกำหนดรูปแบบ หรือเปลี่ยนเส้นทางลิงก์ได้ตลอดเวลา
ระหว่างมีเครื่องหมาย / ต่อท้าย กับไม่มี
Google ให้ความสำคัญกับ URL ที่มี และไม่มีเครื่องหมาย / ต่อท้าย นั่นหมายความว่าในสายตาของ Google ทั้ง 2 URL นี้ ถูกมองว่าแตกต่าง และไม่ซ้ำกันนั่นเอง
example.com/page/
example.com/page
ดังนั้นหากเนื้อหาของเราสามารถเข้าถึงได้จาก URL ทั้งสองอัน ก็อาจทำให้เกิดปัญหา Duplicate Content ได้
หากต้องการตรวจสอบว่าสิ่งนี้เป็นปัญหาหรือไม่ สามารถลองโหลดหน้าเว็บที่มีเครื่องหมาย / และไม่มีเครื่องหมายต่อท้ายดู ซึ่งตามหลักการแล้วจะสามารถโหลดขึ้นเพียงหน้าเว็บเดียวส่วนลิงก์อีกอันจะถูกเปลี่ยนเส้นทาง
ยกตัวอย่างเช่น หากลองกดเข้าหน้าเว็บนี้โดยไม่มีเครื่องหมาย / ต่อท้าย สุดท้ายก็จะถูกเปลี่ยนเส้นทางให้กลับมายัง URL ที่มีเครื่องหมายต่อท้ายอยู่ดี
โดย Google ชอบเคสแบบนี้มาก เพราะหากสามารถเข้าเว็บไซต์จากลิงก์ได้เพียงเวอร์ชันเดียว แล้วอีกลิงก์ถูกเปลี่ยนเส้นทางให้กลับมายัง URL เดียวกัน จะสามารถลดเนื้อหาที่ซ้ำกันได้นั่นเอง
วิธีแก้ปัญหา
เปลี่ยนเส้นทางเวอร์ชันลิงก์ที่ไม่พึงประสงค์ เช่น ไม่มีเครื่อง / ต่อท้าย ให้กลับไปยังเวอร์ชันที่ต้องการ โดยควรตรวจสอบให้แน่ใจว่าเป็นการลิงก์ที่เชื่อมโยงกันภายในเว็บไซต์ พยายามอย่าสลับไปลิงก์ไปยังลิงก์ที่มีเครื่องหมายบ้าง หรือไม่มีบ้าง ควรยึดหลักไว้หนึ่งอัน แล้วทำการเชื่อมโยงไปเลย
URLs ของ Print-friendly
เว็บไซต์ที่ถูกจัดเก็บ หรือพรินต์ออกมาจะมีเนื้อหาเหมือนกับต้นฉบับทุกประการ โดยมีเพียง URL เท่านั้นที่แตกต่าง เช่น
example.com/page
example.com/print/page
วิธีแก้ปัญหา
Canonicalize เวอร์ชันลิงก์ของ Print-friendly ให้เป็นต้นฉบับ
URLs ของ Mobile-friendly
เนื้อหาของเวอร์ชัน Mobile-friendly นั้นถูกคัดลอกมาคล้ายกับของ Print-friendly แตกต่างกันแค่หน้าตาของลิงก์เท่านั้น คือ
example.com/page
m.example.com/page
วิธีแก้ปัญหา
ทำการ Canonicalize ลิงก์ของ Print-friendly ให้เป็นต้นฉบับ โดยใช้ rel=“alternate” เพื่อบอก Google ว่า URL นี้เป็นเพียงอันที่เหมาะสมกับอุปกรณ์เคลื่อนที่ และเป็นเนื้อหาทางเลือกจากเวอร์ชันเดสก์ท็อปเท่านั้น
URLs ของ AMP
AMP หรือ Accelerated Mobile Pages ก็เป็นเนื้อหาที่ซ้ำเช่นเดียวกัน แตกต่างเพียงหน้าตาของ URL
example.com/page
example.com/amp/page
วิธีแก้ปัญหา
ทำการ Canonicalize ลิงก์เวอร์ชัน AMP ให้เป็น non-AMP โดยใช้ rel=”amphtml” เพื่อบอก Google ว่า URL ของ AMP นี้เป็นเพียงลิงก์เวอร์ชันทางเลือกของเนื้อหาที่ไม่ใช่ AMP เท่านั้น
แต่ถ้าหากมีแค่เนื้อหาแบบ AMP ก็อาจเปลี่ยนไปใช้ Canonical แท็ก ที่อ้างอิงถึงตัวเองได้
Tags และหน้าหมวดหมู่
ระบบจัดการเนื้อหาของเว็บไซต์ หรือ CMS ส่วนใหญ่จะสร้างหน้าแท็ก ก็ต่อเมื่อมีการใช้แท็กเท่านั้น
ยกตัวอย่างเช่น หากเรามีบทความที่เขียนเกี่ยวกับเวย์โปรตีนออร์แกนิก และมีการใช้ทั้ง ‘โปรตีนผง’ และ ‘เวย์’ เป็นแท็ก ก็จะพบกับหน้าแท็กทั้งสองดังนี้
https://www.caltonnutrition.com/tag/whey/
https://www.caltonnutrition.com/tag/protein-powder/
ซึ่งนั่นก็ไม่ได้ทำให้เกิด Duplicate Content เสมอไป แต่ก็สามารถเกิดขึ้นได้ จากตัวอย่างภาพด้านล่างที่ถึงแม้เว็บไซต์นี้จะมี URL ถึง 2 แท็ก แต่ตัวเนื้อหามีเพียงหน้าเดียว ดังนั้นแท็กแต่ละหน้าจึงมีคอนเทนต์ที่เหมือนกันนั่นเอง
วิธีแก้ปัญหา
มีอยู่สองทางเลือก คือ
- หลีกเลี่ยงการใช้ tags เพราะโดยทั่วไปแล้วการใช้ หรือไม่ใช้แทบจะไม่ส่งผลอะไรเลย
- ทำ Noindex ที่หน้า Tags ซึ่งวิธีการนี้ไม่สามารถลดค่าใช้จ่าย หรือแก้ปัญหางบประมาณในการรวบรวมข้อมูลได้ เนื่องจาก Google ยังคงมีการเข้ารวบรวมข้อมูลในหน้าเว็บเหล่านี้อยู่
และข้อควรระวังอีกอย่างคือ หน้าหมวดหมู่เองก็อาจทำให้เกิดปัญหาเดียวกันกับหน้าเว็บที่ใช้ tags โดยอ้างอิงจากกรณีนี้
https://www.xs-stock.co.uk/adidas/
https://www.xs-stock.co.uk/brands/Chelsea-FC.html
โดยเว็บไซต์ทั้งสองหน้านี้แทบจะเหมือนกัน เพราะไม่ได้มีรายการผลิตภัณฑ์อยู่ในหมวดหมู่ใดหมวดหมู่หนึ่ง จึงทำให้เกิดสำเนาสำเร็จรูปเพียงเท่านั้น
ซึ่งสามารถแก้ไขได้โดยการใช้จำนวนหมวดหมู่ที่เหมาะสมบนเว็บไซต์ หรือทำ Noindexing ที่หน้าหมวดหมู่ไปเลยนั่นเอง
URLs ของรูปภาพที่แนบมา
ระบบจัดการเนื้อหาเว็บไซต์จำนวนมากมีการสร้างหน้าเฉพาะขึ้นมาสำหรับไฟล์ภาพโดยเฉพาะ ซึ่งโดยปกติแล้วหน้าเหล่านั้นจะไม่แสดงอะไรเลยนอกจากรูปภาพ และสำเนาสำเร็จรูปบางส่วนเท่านั้น
แต่สำเนานี้จะเหมือนกันในทุกหน้าที่ถูกสร้างขึ้นอัตโนมัติ ดังนั้นจึงมีความเสี่ยงที่อาจทำให้เกิดเนื้อหาซ้ำได้นั่นเอง
วิธีแก้ปัญหา
ปิดการใช้งานหน้าเว็บเฉพาะรูปภาพบน CMS หรือระบบจัดการเนื้อหาของตนเองใน WordPress ซึ่งสามารถทำได้โดยการใช้ปลั๊กอิน เช่น Yoast เป็นต้น
Paginated comments
WordPress และ CMS อื่น ๆ หลายตัว มีการอนุญาตให้จัดทำ Paginated comments หรือเนื้อหาแบบแบ่งหน้าได้ ซึ่งอาจทำให้เกิดเนื้อหาซ้ำได้จากการสร้าง URL เดียวกันในหลายเวอร์ชัน
example.com/post/
example.com/post/comment-page-2
example.com/post/comment-page-3
วิธีแก้ปัญหา
ปิดการใช้งาน Paginated comments ไป หรือ noindex หน้าที่ถูกแบ่งออกมา จากการใช้ปลั๊กอิน Yoast
การรองรับหลายพื้นที่
หากเราแสดงเนื้อหาที่คล้ายกันให้แก่ผู้คนในหลากหลายพื้นที่ โดยมีการใช้ภาษาเดียวกัน นั่นก็อาจเป็นอีกหนึ่งสาเหตุที่ทำให้เกิด Duplicate Content ได้
ยกตัวอย่างเช่น อาจมีเว็บไซต์หลายเวอร์ชันเพื่อรองรับการใช้งานสำหรับผู้คนที่อาศัยอยู่ในประเทศอเมริกา อังกฤษ และออสเตรเลีย ซึ่งเนื้อหาอาจมีความแตกต่างกันเพียงเล็กน้อยในแต่ละพื้นที่ เช่น ราคาอาจเปลี่ยนจากดอลลาร์เป็นปอนด์ แต่ส่วนอื่น ๆ แทบจะซ้ำกันทั้งหมด
วิธีแก้ปัญหา
ใช้แท็ก hreflang เพื่อบอกเครื่องมือค้นหาเกี่ยวกับความสัมพันธ์ของหน้าเว็บรูปแบบต่าง ๆ
หน้าผลรวมการค้นหา
เว็บไซต์ส่วนมากมักมีช่องค้นหา ซึ่งโดยทั่วไปแล้วเมื่อกรอกสิ่งที่ต้องการลงไปก็จะถูกนำไปยังหน้า URL ที่มีการกำหนดพารามิเตอร์ไว้ ยกตัวอย่างเช่น example.com?q=search-term
โดย Matt Cutt อดีตหัวหน้าฝ่ายเว็บสแปมของ Google ได้กล่าวไว้ว่า
“ทั่วไปแล้วผลการค้นหาเว็บจะไม่เพิ่มคุณค่าให้กับผู้ใช้ เนื่องจากเป้าหมายหลักของเราคือ การนำเสนอผลการค้นหาที่ดีที่สุดเท่าที่จะเป็นไปได้ จึงไม่มีการรวมผลการค้นหาจากตัวชี้วัดของเรา และแน่นอนว่าไม่ใช่ทุก URL ที่ประกอบด้วยคำว่า “/results” or “/search” จะเป็นผลการค้นหาทั้งหมด”
วิธีแก้ปัญหา
ใช้ Robot Meta Tags หรือการเขียนคำสั่งเพื่อไม่ให้ Search Engine แสดงผลของหน้าเว็บนั้น และลบหน้าการค้นหาออกจากดัชนีตัวชี้วัดของ Google หรือบล็อกการเข้าถึงหน้าผลการค้นหาใน robot.txt เพื่องดเว้นการเชื่อมโยงจากภายในไปยังผลการค้นหานั่นเอง
Staging environment
Staging environment หรือขั้นตอนการดูแลความเรียบร้อยทั้งหมดก่อนเอาเว็บขึ้นระบบ อาจก่อให้เกิดเวอร์ชันที่ซ้ำกัน หรือคล้ายกันของเว็บที่ถูกใช้เพื่อทำการทดสอบได้
ยกตัวอย่างเช่น เราอาจต้องการติดตั้งปลั๊กอินใหม่ หรือเปลี่ยนแปลงโค้ดบางส่วนบนเว็บไซต์โดยที่ไม่ต้องการให้การดำเนินการดังกล่าวไปกระทบกับเว็บไซต์หลักที่มีผู้เยี่ยมชมหลายแสนคนต่อวัน เพราะอาจก่อให้เกิดความเสี่ยงต่อการผิดพลาดมากเกินไป ดังนั้นจึงต้องมีการทำ Staging environment หรือสร้างสภาพแวดล้อมชั่วคราวขึ้นมา
แต่สิ่งนี้อาจกลับกลายเป็นปัญหาต่อ SEO ก็ต่อเมื่อ Google มีการรวบรวมข้อมูล และจัดทำดัชนีชี้วัดในหน้าเว็บชั่วคราวเหล่านั้นด้วย ซึ่งเป็นสาเหตุที่ทำให้เกิด Duplicate Content ขึ้นมานั่นเอง
วิธีแก้ปัญหา
ปกป้องการเข้าถึงหน้าเว็บชั่วคราวของเราโดยใช้การยืนยัน HTTP, รายการ IP ที่ได้รับอนุญาตเป็นพิเศษ รวมถึงระบบ VPN ได้ แต่ถ้าหากมีการจัดทำดัชนีที่หน้าเว็บเหล่านั้นไปแล้ว ก็สามารถใช้คำสั่ง noindex เพื่อนำออกได้
วิธีตรวจสอบ และแก้ไขเนื้อหาที่ซ้ำกันบนเว็บของตัวเอง
ไปที่เครื่องมือ Site Audit ของ Ahrefs และเริ่มการรวบรวมข้อมูล
เมื่อเสร็จแล้ว ให้ไปที่รายงาน Content quality และมองหารายการที่ซ้ำ หรือคล้ายกัน โดยไม่มีการทำ canonical ซึ่งจะอยู่ในแถบสีส้ม

เลือกคลิกอันใดอันหนึ่งเพื่อดูหน้าเว็บที่ได้รับผลกระทบ
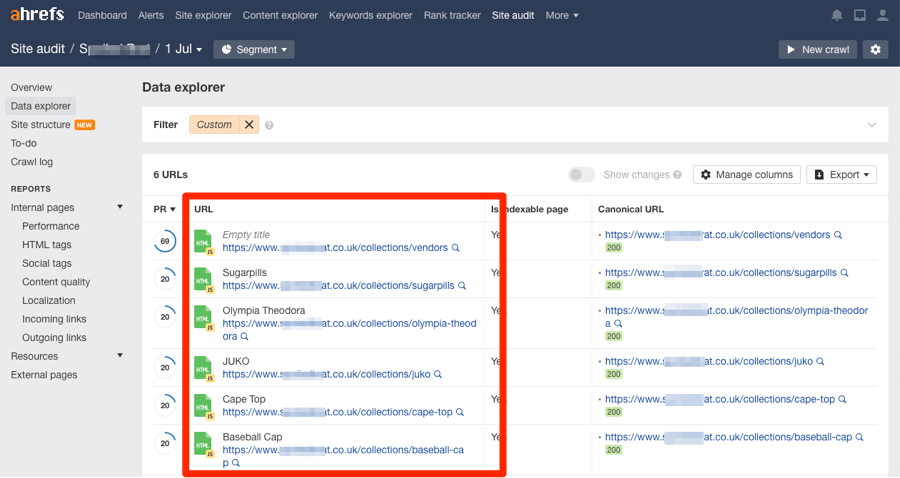
ตรวจสอบสาเหตุที่ทำให้เกิด Duplicate Content และดำเนินการตามความเหมาะสม
มีคำแนะนำอย่างหนึ่งว่าหน้าเว็บเหล่านี้อาจไม่ได้เป็นปัญหาที่ต้องได้รับการแก้ไขเสมอไป โดยเฉพาะอย่างยิ่งในหน้าเว็บที่แค่คล้าย หรือเกือบมีเนื้อหาซ้ำ แต่อาจไม่ได้ซ้ำกันทั้งหมด
ไม่ได้ใช้งาน Ahrefs อย่างนั้นหรอ ?
ลองค้นหาคำเตือนที่เกี่ยวข้องกับการทำเนื้อหาซ้ำเหล่านี้ใน Google Search Console ได้ ว่ามีอะไรบ้าง
- ทำซ้ำโดยไม่มีการใส่ canonical ที่ผู้ใช้เลือก
- ซ้ำจากการที่ Google เลือก canonical แตกต่างจากผู้ใช้
- ซ้ำจากการที่ URL ที่ส่งมาไม่ได้ถูกเลือกเป็น canonical
มาเรียนรู้วิธีจัดการกับปัญหาเหล่านี้เพิ่มเติมกัน
หากต้องการรู้ว่า Google ปฏิบัติ หรือมอง URL แบบเฉพาะเหล่านี้อย่างไร สามารถใช้เครื่องมือ URL Inspection tool ตรวจสอบได้
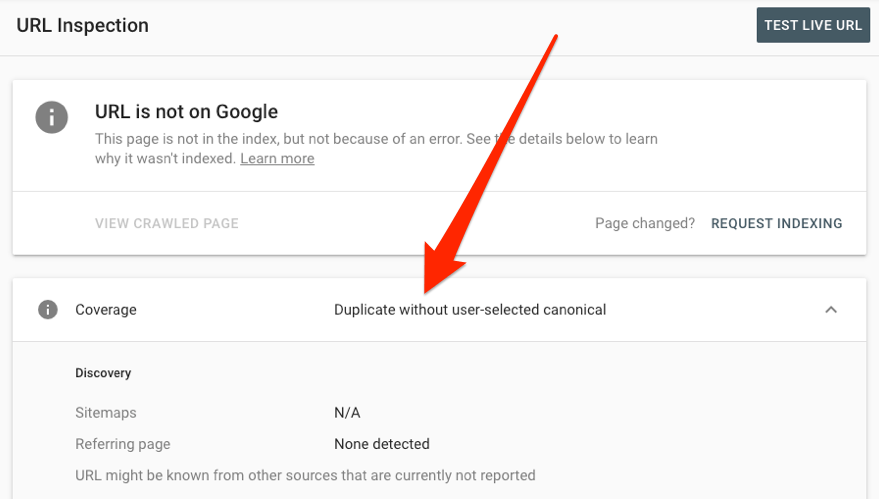
นอกจากนี้ยังสามารถตรวจสอบ title tags ที่ซ้ำกัน รวมถึง meta descriptions และ H1 ในรายงานของ HTML tags ได้อีกด้วย
รายการเนื้อหาซ้ำ คือสิ่งที่เรามองหา โดยหน้าเว็บเหล่านี้คือหน้าที่มี meta tags ซ้ำกัน แต่มีในส่วนการบัญญัติ หรือ canonical ต่างกันนั่นเอง
ให้ทำการเลือกเฉพาะ “Bad duplicates” ที่แถบด้านล่างของ HTML tags & content

แล้วทำการคลิกไปที่แถบเส้นสีเหลืองตรงไหนก็ได้เพื่อดูหน้าเว็บที่ได้รับผลกระทบ โดยเว็บไซต์ที่มี titles, meta descriptions และ H1 ซ้ำกัน มักมีจุดที่คล้ายกันมาก
ยกตัวอย่างเช่น สองเว็บนี้มี title tag เหมือนกัน และตัวเนื้อหาก็แทบจะคล้ายกันทั้งหมด เนื่องจากเขียนถึงสินค้าตัวเดียวกันนั่นเอง โดยมีสิ่งที่แตกต่างกัน คือ หน้าเว็บหนึ่งถูกจัดทำขึ้นเกี่ยวกับไฟส่องสว่างแบบทันทีจำนวน 3 แพ็ก ขณะที่อีกหน้าเว็บหนึ่งขายแบบแพ็กเดียว
ซึ่ง Google ได้มีการระบุว่าในกรณีแบบนี้ เราควรที่จะย่อเนื้อหาที่คล้ายกันให้เหลือน้อยที่สุด
“หากมีหน้าเว็บไซต์ที่คล้ายกัน ให้ผู้ใช้พิจารณาขยายแต่ละหน้า หรือรวมหน้าต่าง ๆ ให้กลายเป็นหน้าเดียว”
แต่อย่างไรก็ตามหากมีจำนวนหน้าที่ซ้ำกันอยู่ไม่มาก ก็อาจไม่ได้เป็นปัญหาอย่างที่คิด
วิธีตรวจสอบ และแก้ไขเนื้อหาที่ซ้ำกันบนเว็บไซต์อื่น
การคัดลอก และเผยแพร่เนื้อหาโดยที่ไม่ได้รับอนุญาตจากเว็บไซต์อื่นอาจทำให้เกิดปัญหา Duplicate Content ได้ แต่ปัญหาจะรุนแรงขึ้นก็ต่อเมื่อพบว่าเว็บไซต์ที่คัดลอกเนื้อหาไปอยู่อันดับที่สูงกว่าเรา และยิ่งร้ายแรงหากเกิดขึ้นกับเว็บไซต์ใหม่ หรือเว็บไซต์ขนาดเล็กที่ยังไม่มีฐานผู้ชมมากนัก เนื่องจากเว็บที่คัดลอกเนื้อหาอาจได้รับความน่าเชื่อถือมากกว่า จนสามารถหลอก Google ได้ว่าหน้าเว็บนั้นคือ เนื้อหาที่เป็นต้นฉบับ นั่นเอง
หากเว็บไซต์ของเรามีขนาดเล็ก อาจค้นหาเว็บไซต์ที่คัดลอกมาจากการดึงตัวอย่างประโยค หรือคำพูดมาค้นหาใน Google ได้

แต่สำหรับเว็บไซต์ขนาดใหญ่ อาจจำเป็นต้องพึ่งเครื่องมืออัตโนมัติ เช่น Copyscape ในการช่วยค้นหาเว็บไซต์ที่มีเนื้อหาซ้ำกันในส่วนอื่น ๆ
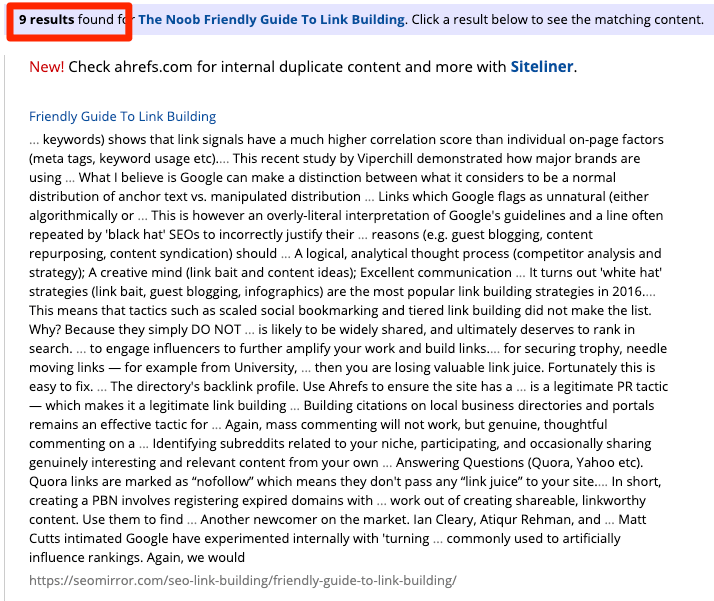
โดยไม่ว่าจะใช้วิธีใดก็ตาม ผลลัพธ์ที่ค้นหาเจอส่วนใหญ่มักมาจากเว็บสแปม หรือเว็บไซต์คุณภาพต่ำ ซึ่งทั่วไปแล้วก็ไม่มีอะไรต้องกังวล หากเราเห็นว่าเว็บไซต์นั้นมีการคัดลอกเนื้อหา และอาจขโมยผู้ชมของไป ก็สามารถตรวจสอบได้โดยการใส่ URL ของเว็บไซต์นั้นลงไปที่ฟังก์ชัน Site Explorer ของ Ahrefs เพื่อดูจำนวนการเยี่ยมชมได้
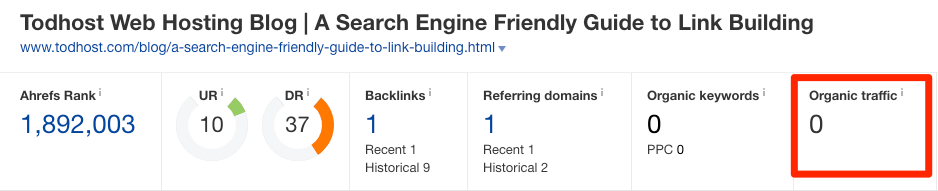
หากตรวจสอบแล้วพบว่าเว็บไซต์ที่คัดลอกไปมียอดการเข้าชมมากกว่าเว็บต้นฉบับของตัวเอง ก็จำเป็นต้องเริ่มการแก้ไขต่าง ๆ ดังนี้
- ติดต่อ และขอให้พวกเขาลบเนื้อหาออก
- ติดต่อ และขอให้พวกเขาเพิ่ม canonical link กลับมายังเว็บต้นฉบับของเรา เพื่อช่วยให้ Google จดจำ และแยกแยะเว็บไซต์ได้อย่างถูกต้อง
- ส่งคำขอผ่าน Google เพื่อให้ลบเว็บนั้นออกตาม รัฐบัญญัติลิขสิทธิ์แห่งสหัสวรรษดิจิทัล หรือ DMCA
แต่หากในกรณีที่เรามีความตั้งใจที่จะเผยแพร่เนื้อหาไปยังเว็บไซต์อื่นด้วยตัวเอง ก็ควรลองขอให้เจ้าของเว็บเหล่านั้นเพิ่ม canonical links กลับมายังเว็บต้นฉบับของตัวเองด้วย ซึ่งจะช่วยลดความเสี่ยงการเกิดปัญหา Duplicate Content ได้
การลงเนื้อหาซ้ำในเว็บของตัวเอง
หากเรากำลังลงเนื้อหาซ้ำจากเว็บไซต์อื่นบนเว็บของตัวเอง ก็มีอยู่ 2 วิธีในการป้องกันปัญหา Duplicate Content คือ
- ทำการ Canonicalize กลับไปยังเว็บต้นฉบับ
- ทำ Noindex ให้กับหน้าเว็บนั้น
สรุป
อย่ากดดัน หรือเครียดเกินไปหากพบว่าเกิดปัญหา Duplicate Content ขึ้นกับตัวเอง เพราะเรื่องราวอาจไม่เลวร้ายอย่างที่คิด
หากเรามีเว็บไซต์ที่มีเนื้อหาซ้ำ หรือเกือบซ้ำกันอยู่ในมือเพียงจำนวนหนึ่ง ก็อาจไม่ได้ส่งผลกระทบมากนัก เนื่องจากเนื้อหาที่ซ้ำกัน หรือเนื้อหาสำเร็จรูปที่ถูกคัดลอกมาจำนวนเล็กน้อยนั้น ถือเป็นเรื่องปกติสำหรับ Google โดยทาง Google เองก็มีระบบ และมาตรฐานในการจัดการดูแลกับสิ่งเหล่านี้อยู่แล้ว
หากมีสิ่งที่ควรกังวลจริง ๆ ก็ควรระวังข้อผิดพลาดทางเทคนิค SEO ที่อาจนำไปสู่การสร้างเนื้อหาที่ซ้ำกันหลายร้อยหลายพันหน้าจะดีกว่า ยกตัวอย่างเช่น การใช้ระบบนำทางแบบประกอบ หรือฟิลเตอร์อย่างไม่เหมาะสมในหน้าเว็บอีคอมเมิร์ซ
ซึ่งสิ่งเหล่านี้คือ ปัญหาร้ายแรงอย่างแท้จริงที่อาจสร้างความเสียหายให้แก่เว็บไซต์ และทำให้สูญเสียงบประมาณการรวบรวมข้อมูลอย่างมหาศาลไปฟรี ๆ เลยนั่นเอง
ใครที่อยากหาความรู้เพิ่มเติมเกี่ยวกับการทำ SEO สามารถตามอ่านบทความอื่น ๆ ได้ที่ : https://thekalling.com/tkl-blog/

