

วันนี้จะพาทุกคนมาทำความรู้จักกับ Robots Meta Tag ให้มากขึ้น ซึ่งต้องบอกเลยว่าแท็กนี้ไม่สามารถใช้ในการควบคุมการจัดทำดัชนีได้ แล้วสิ่งนี้คืออะไร อธิบายได้ง่าย ๆ ว่าเป็นคำสั่ง หรือสัญญาณที่ระบุไว้ไม่ให้เครื่องมือค้นหา (Search Engine) แสดงหน้าเว็บไซต์ต่อผู้ค้นหานั่นเอง ดังนั้นกลไกการทำงานของแท็กนี้จึงไม่ได้ใช้เพื่อบ่งชี้การจัดทำดัชนีหน้าเว็บไซต์โดยตรง
สารบัญเนื้อหา
- ความหมายของ Robots meta tag คืออะไร
- แท็ก Meta Robots มีความสำคัญต่อ SEO หรือไม่
- การกำหนดคุณลักษณะองค์ประกอบของแท็ก Meta Robots
- วิธีการตั้งค่าแท็ก Meta Robotes
- เรียนรู้ X-Robots-Tag คืออะไร
ความหมายของ Robots meta tag คืออะไร
เมื่อรู้จักความหมายและหน้าที่ของแท็กนี้ไปกันคร่าว ๆ แล้ว ต่อมาจะลงลึกอธิบายเพิ่มเติมให้เข้าใจกันมากขึ้น ซึ่งแท็กนี้ คือ ข้อมูลโค้ด HTML ที่ใช้ในการบอกเครื่องมือค้นหาว่าจะสามารถหรือไม่สามารถทำอะไรได้บ้างในหน้าเว็บไซต์หนึ่ง ๆ โดยช่วยในการควบคุมการรวบรวมข้อมูล การจัดทำดัชนี และกำหนดวิธีแสดงข้อมูลจากหน้าเว็บไซต์ในผลการค้นหา ซึ่งแท็กนี้จะวางไว้ที่ส่วนหัว <head> ของหน้าเว็บ
ตัวอย่าง
<meta name="robots" content="noindex, nofollow">แท็ก Meta Robots มีความสำคัญต่อ SEO หรือไม่
ถ้าถามว่าแท็กนี้มีความสำคัญต่อ SEO หรือไม่ ขอตอบว่า “ใช่ สำคัญ” เนื่องจากว่าสามารถใช้เพื่อป้องกันไม่ให้หน้าเว็บไซต์ปรากฏในผลการค้นหา ซึ่งมีเนื้อหาหลายประเภท เช่น ข้อมูลส่วนบุคคล ที่จำเป็นต้องป้องกันไม่ให้เครื่องมือค้นหาจัดทำดัชนีหน้าเว็บนั้น ๆ
ซึ่งหน้าเว็บไซต์ที่ไม่ควรปรากฏบนผลการค้นหา มีดังนี้
- หน้าเว็บไซต์ที่ไม่สร้างคุณค่า หรือประโยชน์ให้กับผู้ค้นหา
- หน้าเว็บไซต์ที่ยังไม่พร้อมใช้งาน
- หน้าสำหรับแอดมิน และหน้าเพจขอบคุณ
- ผลการค้นหาภายใน
- หน้า PPC landing
- หน้าที่เกี่ยวกับโปรโมชั่น ข้อมูลการแข่งขัน หรือหน้าที่ผลิตภัณฑ์ที่กำลังจะเปิดตัว
- เนื้อหาที่ซ้ำกัน (Duplicate Contents) ซึ่งสามารถใช้ Canonical tags ในการกำหนดเวอร์ชันหลักได้ เพื่อจัดทำดัชนี
โดยทั่วไปแล้ว หากเว็บไซต์ของคุณมีขนาดใหญ่ การจัดการและควบคุมการรวบรวมข้อมูล และการจัดทำดัชนีของเครื่องมือค้นหาจะยากมากขึ้น ดังนั้นจำเป็นต้องใช้ robots.txt เข้ามาช่วย รวมทั้งการวางโครงแผนผังเว็บไซต์ หรือ sitemaps ที่เป็นระเบียนและถูกต้องจะส่งผลดีต่อ SEO เป็นอย่างมาก
การกำหนดคุณลักษณะองค์ประกอบของแท็ก Meta Robots
แท็กนี้มีองค์ประกอบ (Attributes) อยู่ 2 ส่วน ได้แก่ ชื่อ และเนื้อหา ซึ่งจะต้องระบุค่าขององค์ประกอบเหล่านี้ ดังนั้นมาเรียนรู้เพิ่มเติมกันดีกว่าว่าต้องทำอะไรบ้าง
แอตทริบิวต์ชื่อและ user-agent (UA)
สำหรับ Name Attribute จะใช้ระบุว่าโปรแกรมรวบรวมข้อมูลอะไรบ้าง ซึ่งจำเป็นต้องปฏิบัติตามนั้น ซึ่งค่านี้สามารถเรียกอีกชื่อหนึ่งว่า user-agent (UA ในการที่โปรแกรมรวบรวมข้อมูลจำเป็นต้องมีการระบุ UA เพื่อขอเพจ UA แสดงถึงเบราว์เซอร์ที่คุณใช้ โดย user-agent ของ Google ได้แก่ Googlebot หรือ Googlebot-image
ค่า UA “robots” ใช้กับโปรแกรมรวบรวมข้อมูลทั้งหมด นอกจากนั้นยังเกี่ยวข้องกับการเพิ่มเมตาแท็กโรบ็อตลงในส่วน <head> ของเว็บไซต์ได้อีกด้วย ตัวอย่างเช่น หากคุณต้องการป้องกันไม่ให้รูปภาพปรากฏในการค้นหาของ Google หรือ Bing สามารถเพิ่มเมตาแท็กต่อไปนี้ในการกำหนดค่าได้
<meta name="googlebot-image" content="noindex">
<meta name="MSNBot-Media" content="noindex">แอตทริบิวต์เนื้อหาและคำสั่งการรวบรวมข้อมูล/การจัดทำดัชนี
Content Attribute จะให้คำแนะนำเกี่ยวกับวิธีการรวบรวมช้อมูลและจัดทำดัชนีข้อมูลบนหน้าเว็บเมื่อไม่มีเมตาแท็กโรบ็อต โปรแกรมรวบรวมข้อมูลจะตีความว่าจะต้องจัดทำดัชนี และติดตามหน้านั้น ๆ ซึ่งจะทำให้เพจแสดงในผลการค้นหา และเครื่องมือสามารถเข้ารวบรวมข้อมูลลิงก์ทั้งหมดบนเพจได้ แต่มีอีกหนึ่งวิธีที่ป้องกันการติดตามจากเครื่องมือการค้นหา คือ แนะนำให้ใช้แท็ก rel=”nofollow”
ซึ่ง content attribute ใน Google มีอะไรบ้างมาดูกันเลย
- all
ค่าเริ่มต้นของ “index, follow” ไม่จำเป็นต้องใช้คำสั่งนี้
<meta name="robots" content="all"> - noindex
ใช้ในการสั่งเครื่องมือค้นหาไม่ให้จัดทำดัชนีหน้าเว็บ เพื่อป้องกันไม่ให้แสดงหน้าเว็บในผลการค้นหา
<meta name="robots" content="noindex">- nofollow
ใช้ในการสั่งไม่ให้ robots รวบรวมข้อมูลลิงก์ทั้งหมดบนหน้าเว็บ แต่อย่างไรก็ตาม URL เหล่านี้ก็ยังสามารถจัดทำดัชนีได้
<meta name="robots" content="nofollow"> - none
การใช้งานรวมกันของ noindex, nofollow เป็นสิ่งที่ควรหลีกเลี่ยง เนื่องจากเครื่องมือค้นหาอื่น ๆ เช่น Bing จะไม่รองรับคำสั่งนี้
<meta name="robots" content="none">- noarchive
ใช้เพื่อป้องกันไม่ให้ google แสดงสำเนาแคชของเพจใน SERP
<meta name="robots" content="noarchive">- notranslate
ใช้เพื่อป้องกันไม่ให้ Google เสนอการแปลหน้าเว็บใน SERP
<meta name="robots" content="notranslate">- noimageindex
ป้องกันไม่ให้ Google จัดทำดัชนีภาพที่ฝังอยู่ในหน้า
<meta name="robots" content="noimageindex">- unavailable_after:
ใช้สำหรับบอก Google ไม่ให้แสดงหน้าเว็บไซต์ในผลการค้นหาหลังจากกำหนดวันที่/เวลาที่ระบุไว้ โดยพื้นฐานแล้วคำสั่ง noindex พร้อมไทม์เมอร์ จะต้องระบุวันที่/เวลา โดยใช้รูปแบบ RFC 850
<meta name="robots" content="unavailable_after: Sunday, 01-Sep-19 12:34:56 GMT"> - nosnippet
ใช้ในการกำหนดเลือกไม่รับข้อความและตัวอย่างวิดีโอทั้งหมดภายใน SERP นอกจากนี้ยังทำงานเป็น noarchive ในเวลาเดียวกัน
<meta name="robots" content="nosnippet">ข้อความทราบ
ตั้งแต่เดือนตุลาคม 2019 ทาง Google ได้เสนอตัวเลือกที่ละเอียดยิ่งขึ้นเพื่อควบคุมว่าคุณต้องการแสดงตัวอย่างข้อมูลในผลการค้นหาหรือไม่และอย่างไร ส่วนหนึ่งเป็นผลมาจาก European Copyright Directive ซึ่งฝรั่งเศสบังคับใช้เป็นครั้งแรกพร้อมกับกฎหมายลิขสิทธิ์ฉบับใหม่
ซึ่งกฏหมายฉบับนี้มีผลต่อเจ้าของเว็บไซต์ทุกคน เนื่องจาก Google จะไม่แสดงตัวอย่างข้อมูลทั้งข้อความ รูปภาพ หรือวิดีโอ จากเว็บไซต์ของคุณให้แก่ผู้ใช้ในประเทศฝรั่งเศสอีกต่อไป เว้นแต่คุณจะเลือกใช้เมตาแท็กโรบ็อตใหม่ที่กำหนดขึ้นมา
ดังนั้นแนะนำวิธีแก้ปัญหาอย่างรวดเร็ว เพียงเพิ่มข้อมูลโค้ด HTML ด้านล่างนี้ในทุกหน้าบนเว็บไซต์ของคุณ เพื่อบอก Google ว่าคุณไม่ต้องการมีข้อจำกัดสำหรับข้อมูลโค้ดของคุณ
<meta name="robots" content=”max-snippet:-1, max-image-preview:large, max-video-preview:-1">หากคุณใช้ Yoast SEO โค้ดส่วนนี้จะถูกเพิ่มโดยอัตโนมัติทุกหน้า เว้นแต่จะเพิ่มคำสั่ง noindex หรือ nosnippet
- max-snippet
ใช้ระบุจำนวนอักขระสูงสุดที่ Google สามารถแสดงในตัวอย่างข้อความได้ เมื่อกำหนดเลขเป็น 0 จะเป็นการเลือกว่าไม่ใช้ตัวอย่างข้อความ ส่วนการกำหนดเลขเป็น -1 หมายถึงไม่จำกัดการแสดงตัวอย่างข้อความ
แท็กต่อไปนี้จะใช้สำหรับการตั้งค่าขีดจำกัดตัวอย่างข้อความไว้ที่ 160 อักขระ
<meta name="robots" content="max-snippet:160"> - max-image-preview:
ใช้แจ้งให้ Google ทราบว่ารูปภาพดังกล่าวสามารถใช้เป็นตัวอย่างรูปภาพได้ และกำหนดขนาดของรูปภาพ ซึ่งใช้กำหนดตัวอย่างรูปภาพได้ ดังนี้
- ไม่ต้องการให้แสดงตัวอย่างรูปภาพ
- ขนาดมาตรฐาน – แสดงรูปภาพตัวอย่างเริ่มต้น
- ขนาดใหญ่ – แสดงตัวอย่างรูปภาพที่ใหญ่ที่สุดเท่าที่จะเป็นไปได้
<meta name="robots" content="max-image-preview:large">ซึ่งขอแนะนำให้ใช้ขนาดใหญ่ และรูปภาพควรมีความกว้างอย่างน้อย 1,200 px เนื่องจากค่าดังกล่าวจะเพิ่มโอกาสในการแสดงรูปภาพใน Google Discover
- max-video-preview
ใช้ในการตั้งค่าจำนวนวินาทีสูงสุดสำหรับการแสดงตัวอย่างวิดีโอ
ตัวอย่างเช่น
แท็กตั้งค่าให้ Google แสดงวิดีโอแสดงได้สูงสุด 15 วินาที
<meta name="robots" content="max-video-preview:15">ข้อควรทราบ
Google ยังแนะนำแอตทริบิวต์ data-nosnippet HTML อีกด้วย คุณสามารถใช้สิ่งนี้เพื่อกำหนดข้อความบางส่วนที่ไม่ต้องการให้ Google ใช้เป็นต้วอย่างข้อมูลได้ ซึ่งแท็กนี้สามารถสร้างในรูปแบบ HTML
<p>This is some text in a paragraph that can be shown as a snippet<span data-nosnippet>excluding this part</span></p><div data-nosnippet>This will not appear in a snippet</div><div data-nosnippet="true">And neither will this</div>- nositelinksserarchbox
ใช้ป้องกันไม่ให้ Google แสดงช่องค้นหา โดยเป็นส่วนหนึงของ sitelink
<meta name="robots" content="nositelinkssearchbox">
- indexifembedded
ใช้ในการอนุญาตให้ Google จัดทำดัชนีเนื้อหาที่ฝังผ่าน iframe หรือ HTML Tags ที่คล้ายกันบนหน้าเว็บไซต์ที่มีคำสั่ง noindex และจะใช้ได้เฉพาะเมื่อมีทั้งสองคำสั่งอยู่ด้วยกัน เช่น
<meta name="robots" content="noindex, indexifembedded">การใช้คำสั่งเหล่านี้ต้องทำอย่างไรบ้าง
SEO ส่วนใหญ่ไม่จำเป็นต้องใช้คำสั่งที่ยุ่งยากมากกว่า noindex และ nofollow แต่การรู้ว่าเรามีตัวเลือกอื่น ๆ อยู่ก็เป็นเรื่องที่ดีมาก แต่อย่างไรก็ตามแท็กคำสั่งที่มีอยู่ใน Bing และ Google จะมีความแตกต่างกันเล็กน้อย ดังภาพด้านล่างนี้

คุณสามารถใช้หลายคำสั่งพร้อมกันและสามารถรวมคำสั่งเข้าด้วยกันได้อีกด้วย แต่ไม่ควรใช้แท็กที่ขัดแย้งกัน หรือมีความคล้ายคลึงกัน
วิธีการตั้งค่าแท็ก Meta Robots
เมื่อคุณทราบแล้วว่าคำสั่งเหล่านี้สามารถทำหน้าที่อะไรได้บ้าง และหน้าตารูปแบบเป็นอย่างไร ก็ถึงเวลาที่จะทดลองใช้แท็กเหล่านี้บนเว็บไซต์แล้ว
Robot meta tags จะอยู่ในส่วนของ <head> ของเพจ ซึ่งหากต้องการแก้ไขโค้ดสามารถใช้ HTML editors เช่น Notepad++ หรือ Brackets แต่ถ้าคุณใช้ cms พร้อม SEO plugins จะเป็นอย่างไรบ้าง เคยสงสัยหรือไม่ ดังนั้นมาดูการทำงานกันเลย
การใช้เมตาแท็กโรบ็อตใน WordPress โดยใช้ Yoast SEO
ไปที่ “Advanced” ซึ่งจะอยู่ตรงใต้ Editing block ของแต่ละโพสต์หรือเพจ โดยสามารถตั้งค่า Robots meta tags ตามความต้องการของคุณ ซึ่งการตั้งค่าจะต้องใช้คำสั่ง “noindex, nofollow”
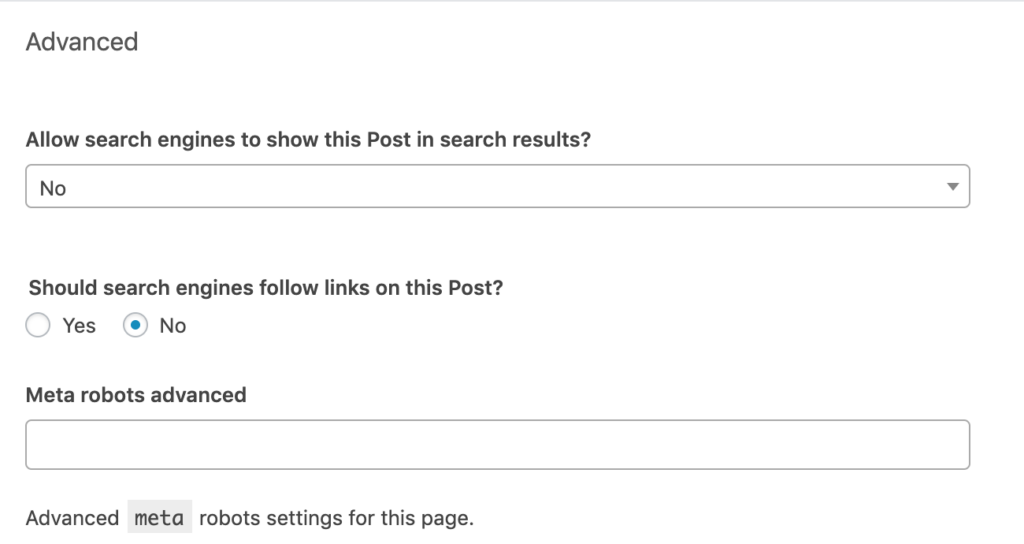
ในแถว “Meta robots advanced” จะมีตัวเลือกให้คุณใช้คำสั่งอื่น ๆ นอกเหนือจาก noindex และ nofollow เช่น noimageindex
นอกจากนั้นคุณยังมีตัวเลือกในการใช้คำสั่งเหล่านี้ได้ทั่วทั้งเว็บไซต์อีกด้วย ซึ่งให้ไปที่ “Search Appearance” ที่อยู่ใน Yoast menu จากนั้นสามารถตั้งค่าเมตาโรบ็อตแท็กในโพสต์ หน้าเพจทั้งหมด หรือเฉพาะการจัดหมวดหมุ่หรือเอกสารสำคัญที่เฉพาะเจาะจงได้

ข้อควรทราบ
การใช้ Yoast ไม่ใช่วิธีการเดียวในการควบคุมเมตาโรบ็อตแท็กใน WordPress ที่มีปลั๊กอิน WordPress SEO อื่น ๆ อีกมากมายที่มีฟังก์ชันการทำงานคล้ายคลึงกัน
X-Robots แท็กคืออะไร
Robots meta tags เหมาะสำหรับการใช้งานคำสั่ง noindex บนหน้า HTML แต่ถ้าต้องการป้องกันไม่ให้เครื่องมือค้นหาจัดทำดัชนีไฟล์ เช่น รูปภาพ หรือ PDF จำเป็นต้องใช้แท็ก X-Robots
ซึ่งแท็กนี้อยู่ในส่วนหัวของ HTTP ที่ส่งจากเว็บเซิร์ฟเวอร์ โดยต่างจากแท็กเมตาโรบ็อตตรงที่ไม่ได้วางไว้ใน HTML ของหน้า มีลักษณะดังนี้:
วิธีที่ง่ายที่สุดในการตรวจสอบ HTTP headers คือ ส่วนขยายเบราว์เซอร์ตรงแถบ Ahrefs SEO toolbar browser extension เพียงไปที่แท็บ HTTP header และดูว่ามี X-Robots-Tag อยู่หรือไม่
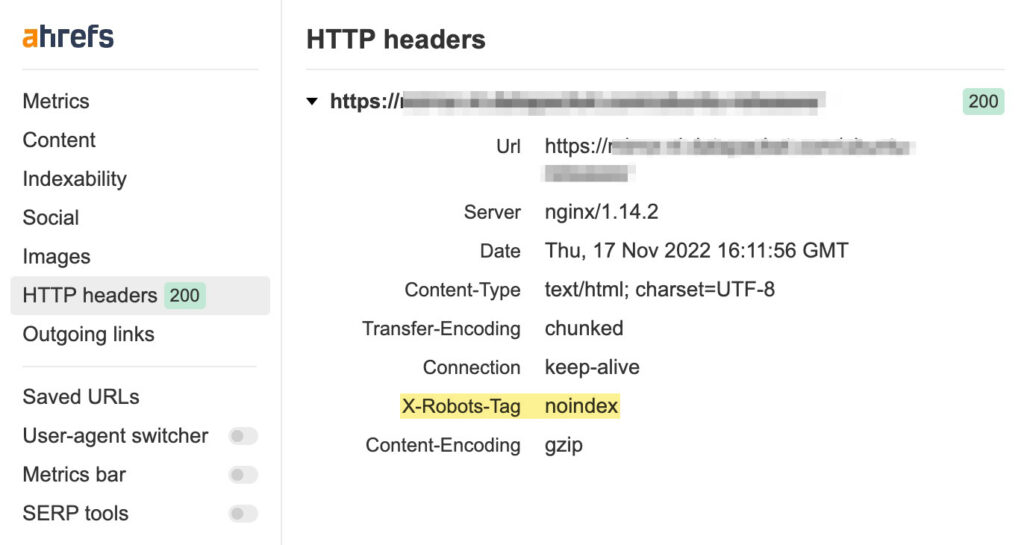
วิธีการตั้งค่า X-Robots-Tag
การกำหนดค่าขึ้นอยู่กับประเภทของเว็บเซิร์ฟเวอร์ที่คุณใช้ และหน้าหรือไฟล์ประเภทใดประเภทหนึ่งที่คุณต้องการเก็บออกจากดัชนี
ลักษณะไลน์ของโค้ดมีดังนี้
Header set X-Robots-Tag “noindex, nofollow”โค้ดไลน์นี้สามารถใช่ได้กับเซิร์ฟเวอร์หลายประเภท ซึ่งเป็นเซิร์ฟเวอร์ที่แพร่หลายมากที่สุด วิธีเพิ่ม HTTP header ที่ใช้งานได้จริงที่สุดคือการแก้ไขไฟล์การกำหนดค่าหลัก โดยปกติมักจะเป็น httpd.conf หรือไฟล์ .htaccess
คุณสามารถใช้คำสั่งเดียวกันสำหรับ X-Robot-Tag เป็น Robots meta tags อย่างไรก็ตามการนำการเปลี่ยนแปลงเหล่านี้ไปใช้ จะต้องให้ผู้มัประสบการณ์หรือเชี่ยวชาญในการทำ เพราะถ้าผิดไวยากรณ์เพียงนิดเดียว อาจจะทำให้เว็บไซต์เสียหายได้
เคล็ดลับมือโปร
หากคุณใช้ CDN ที่รองรับแอปพลิเคชันแบบไร้เซิร์ฟเวอร์สำหรับ Edge SEO คุณสามารถแก้ไขทั้งเมตาแท็ก robots และ X-Robots-Tags บนเซิร์ฟเวอร์ Edge ได้โดยไม่ต้องทำการเปลี่ยนแปลงกับโค้ดเบสพื้นฐาน
รู้หรือไม่ว่าควรใช้ robots meta tag หรือ x-robot เมื่อไหร่
แม้ว่าการเพิ่มข้อมูลโค้ด HTML จะดูเหมือนเป็นตัวเลือกที่ง่ายและตรงไปตรงมาที่สุด แต่ก็อาจไม่ใช่วิธีที่ดีที่สุดในบางกรณี
Non-HTML files
คุณไม่สามารถวางข้อมูลโค้ด HTML ลงในไฟล์ที่ไม่ใช่ HTML เช่น PDF หรือรูปภาพ ดังนั้นจำเป็นต้องใช้วิธี X-Robots-Tag เท่านั้น
ตัวอย่างข้อมูลโค้ดต่อไปนี้ (บนเซิร์ฟเวอร์ Apache) จะกำหนดค่าส่วนหัว noindex HTTP ในไฟล์ PDF ทั้งหมดบนเว็บไซต์
<Files ~ "\.pdf$">
Header set X-Robots-Tag "noindex"
</Files>การใช้คำสั่งในวงกว้าง
หากต้องการใช้ noindex ทั้งในซับโดเมน และซับไดเรกทอรี่ สามารถใช้
x-robots-tags จะทำให้ง่ายขึ้น การแก้ไขในส่วนของ HTTP header สามารถจับคู่กับ URL และชื่อไฟล์ได้โดยใช้นิพจน์ทั่วไปได้ การแก้ไขหน้าเว็บไซต์เป็นจำนวนมากที่ซับซ้อนใน HTML โดยใช้ฟังก์ชันการค้นหาและแทนที่มักจะต้องใช้เวลาจำนวนมากในการแก้ไข
การเข้าชมจากเครื่องมือค้นหาอื่น ๆ ที่ไม่ใช่ Google
Google รองรับการใช้งานทั้ง Robots meta tagsและ X-robots-tags แต่เครื่องมือค้นหาทั้งหมดอาจจะไม่ได้เป็นแบบเดียวกันกับกูเกิ้ล
ตัวอย่างเช่น
Seznam ซึ่งเป็นเครื่องมือค้นหาของประเทศเช็ก ซึ่งรองรับเฉพาะเมตาแท็กโรบ็อตเท่านั้น หากต้องการควบคุมวิธีที่เครื่องมือค้นหานี้ใช้รวบรวมข้อมูล และจัดทำดัชนีหน้าเว็บของคุณ การใช้ x-robots-tags จะทำให้เครื่องมือไม่สามารถทำงานได้ ดังนั้นต้องใช้ข้อมูลโค้ด HTML
วิธีหลีกเลี่ยงข้อผิดพลาดในการรวบรวมข้อมูลและยกเลิกการจัดทำดัชนี
หากต้องการแสดงหน้าที่มีคุณค่าและมีประโยชน์ทั้งหมด และต้องการหลีกเลี่ยงเนื้อหาที่ซ้ำกัน รวมทั้งป้องกันไม่ให้หน้าใดหน้าหนึ่งถูกจัดทำดัชนี หรือแม้กระทั้งต้องการจัดการแก้ไขส่วนต่าง ๆ ของเว็บไซต์ จำเป๋นต้องศึกษาข้อผิดพลาดที่อาจเกิดขึ้นได้ ซึ่งเป็นข้อผิดพลาดเกี่ยวกับคำสั่งของโรบ็อต โดยจะมีอะไรบ้างนั้นมาดูกันเลย
ข้อผิดพลาดประการที่ 1 : การเพิ่มคำสั่ง noindex ไปยังหน้าที่ไม่ได้รับอนุญาตใน robots.txt
แนะนำว่าไม่ควรห้ามไม่ให้เกิดการรวบรวมข้อมูลเนื้อหาที่คุณพยายามจะยกเลิกการจัดทำดัชนีใน robots.txt การทำเช่นนี้จะป้องกันไม่ให้เครื่องมือค้นหารวบรวมจ้อมูลหน้าเว็บซ้ำ และค้นพบคำสั่ง noindex
แต่ถ้าไม่แน่ใจว่าที่ผ่านมาเคยเกิดข้อผิดพลาดอะไรบ้างในเว็บไซต์ จะต้องรวบรวมข้อมูลไซต์ด้วยเครื่องมือฟรีอย่าง Ahrefs Webmaster Tools และค้นหาหน้าเว็บที่มีข้อผิดพลาดซึ่งจะปรากฏข้อความว่า “Noindex page receives organic traffic“ error

Noindex pages จะได้รับการเข้าชมทั่วไปและยังคงได้รับการจัดทำดัชนี หากคุณไม่ได้เพิ่มแท็ก noindex ลงไป ซึ่งอาจเป็นไปได้ว่าเกิดจากการบล็อกการรวบรวมข้อมูลในไฟล์ robots.txt จากนั้นตรวจสอบปัญหาและแก้ไขตามความเหมาะสม
ข้อผิดพลาดประการที่ 2 : การจัดการแผนผังเว็บไซต์ (sitemaps) ที่ไม่ดี
หากกำลังพยายามไม่ให้เนื้อหาจัดทำดัชนีโดยใช้ Robots meta tags หรือ x-robots-tag อย่าลบเนื้อหาออกจากแผนผังเว็บไซต์จนกว่าจะยกเลิกการจัดทำดัชนีได้สำเร็จ ไม่เช่นนั้น Google อาจรวบรวมข้อมูลหน้าเว็บซ้ำได้ช้ากว่า
หากต้องการเร่งกระบวนการ deindexing ให้เร็วขึ้น ให้ตั้งค่า Lastmod date ในแผนผังไซต์เป็นวันที่ที่คุณเพิ่มแท็ก noindex ซึ่งจะช่วยส่งเสริมการรวบรวมข้อมูลซ้ำและการประมวลผลใหม่
ข้อควรทราบ
ในระยะยาวอย่ารวมหน้าที่ไม่มีการจัดทำดัชนีไว้ในแผนผังไซต์ของคุณ เมื่อเนื้อหาถูกยกเลิกการจัดทำดัชนีแล้วให้ลบออกจากแผนผังไซต์ของคุณ และถ้ากังวลว่าเนื้อหาเก่าที่ยกเลิกการจัดทำดัชนีแล้วอาจจะยังคงอยู่ในแผนผังไซต์ของคุณ ให้ตรวจสอบข้อผิดพลาด “Noindex page in sitemap” error ในเครื่องมือฟรี Ahrefs Webmaster Tools

ข้อผิดพลาดประการที่ 3 : ไม่ลบคำสั่ง noindex ออกจากสภาพแวดล้อมการใช้งานจริง
การป้องกันไม่ให้โรบ็อตรวบรวมข้อมูลและจัดทำดัชนีใด ๆ ในสภาพแวดล้อมชั่วคราวถือว่าเป็นแนวทางปฏิบัติที่ดี อย่างไรก็ตามบางครั้งข้อผิดพลาดนี้อาจจะส่งผลให้ปริมาณการใช้งานทั่วไปของคุณลดลง
และที่แย่ไปกว่านั้นอาจจะมีการเปลี่ยนเส้นทาง 301 redirects หาก URL ใหม่มีคำสั่ง noindex หรือไม่อนุญาตใน robots.txt คุณจะยังคงได้รับการเข้าชมทั่วไปจากรายการเก่าเป็นระยะเวลาหนึ่ง Google อาจใช้เวลาถึงสองสามสัปดาห์ในการถอดรหัส URL เก่า
เมื่อใดก็ตามที่มีการเปลี่ยนแปลงดังกล่าวบนเว็บไซต์ ให้เฝ้าระวังดูคำเตือน noindex ในรายงานความสามารถในการจัดทำดัชนี ดังนี้

เพื่อป้องกันปัญหาเดิม ๆ ที่อาจจะเกิดขึ้นในอนาคต ต้องเพิ่มรานการตรวจสอบของทีมนักพัฒนาด้วยคำแนะนำในการลบกฏที่ไม่อนุญาตออกจากrobot.txt และคำสั่ง noindex ก่อนที่จะพุชไปสู่การใช้งานจริง
ข้อผิดพลาดประการที่ 4 : การเพิ่ม URL “ลับ” ให้กับ robots.txt แทนที่จะใช้ noindexing
นักพัฒนาซอฟต์แวร์มักพยายามซ่อนหน้าเกี่ยวกับโปรโมชัน ส่วนลด หรือการเปิดตัวผลิตภัณฑ์ที่กำลังจะมาถึง โดยไม่อนุญาตให้เข้าถึงหน้าเหล่านั้นในไฟล์ robots.txt ของไซต์ ซึ่งการทำเช่นนี้เป็นแนวทางปฏิบัติที่ไม่ได้มีประสิทธิภาพมากนัก เนื่องจากเพจเหล่านี้อาจรั่วไหลได้ง่าย วิธีแก้ไขง่าย ๆ โดยเก็บหน้า “ลับ” ออกจาก robots.txt และไม่มีการจัดทำดัชนีหน้าเหล่านั้นแทน
สรุป
การทำความเข้าใจ การจัดการรวบรวมข้อมูล และการจัดทำดัชนีเว็บไซต์ของคุณอย่างเหมาะสม นับว่าเป็นพื้นฐานสำคัญสำหรับการทำ SEO ซึ่งการใช้แท็กเมตาโรบ็อต และ X-Robot-Tag สามารถทำให้การควบคุมการจัดทำดัชนี และรวบรวมข้อมูลเว็บไซต์ ให้ง่ายและรวดเร็วมากยิ่งขึ้น

